딥러닝의 발전은 자연어 처리(NLP)와 컴퓨터 비전 등 다양한 분야에서 획기적인 변화를 이끌어 왔습니다. 그 중심에는 2017년 "Attention is All You Need" 논문에서 소개된 트랜스포머(Transformer) 모델이 있습니다. 트랜스포머는 기존 RNN의 한계를 극복하며 병렬 연산이 가능하고, 긴 문맥을 효과적으로 학습할 수 있는 셀프 어텐션(Self-Attention) 메커니즘을 도입해 NLP 모델의 성능을 비약적으로 향상시켰습니다. 오늘날 GPT, BERT, T5와 같은 모델들이 모두 트랜스포머 기반으로 설계되었으며, 이는 AI 기술 발전의 핵심이 되고 있습니다.
LSTM을 사용한 RNN 구조

트랜스포머가 등장하기 전, NLP 모델은 주로 순환 신경망(Recurrent Neural Network, RNN) 기반으로 구축되었습니다. RNN은 입력 데이터를 순차적으로 처리하며, 이전 타임스텝(time step)의 정보를 기억하는 구조를 가지고 있어 자연어 처리와 같은 순차 데이터(sequence data) 문제에서 강력한 성능을 발휘했습니다.
하지만 기존 RNN은 기울기 소실(vanishing gradient) 문제로 인해 긴 문맥을 기억하는 데 어려움을 겪었고, 이를 해결하기 위해 LSTM(Long Short-Term Memory) 구조가 등장했습니다.
LSTM 구조
LSTM은 RNN의 한계를 극복하기 위해 셀 상태(cell state) 와 게이트(gate) 메커니즘을 도입했습니다.
- 입력 게이트(Input Gate): 새로운 정보를 셀 상태에 얼마나 반영할지 결정
- 망각 게이트(Forget Gate): 이전 정보를 얼마나 유지할지 결정
- 출력 게이트(Output Gate): 다음 단계로 전달할 정보를 결정
이러한 구조를 통해 LSTM은 장기 의존성(long-term dependency)을 보다 잘 학습할 수 있으며, 기울기 소실 문제를 완화할 수 있었습니다.
LSTM의 한계
LSTM은 기존 RNN보다 향상된 성능을 제공했지만, 여전히 몇 가지 중요한 한계를 가지고 있었습니다.
- 순차적 처리의 한계
- RNN과 LSTM은 입력 데이터를 순서대로 처리해야 하므로 병렬 연산이 어렵습니다. 이는 학습 속도를 저하시킵니다.
- 장기 의존성 문제
- LSTM이 RNN보다 더 긴 문맥을 학습할 수 있지만, 여전히 문맥이 너무 길어지면 정보를 잃어버리는 문제가 발생합니다.
- 메모리와 연산 비용
- LSTM의 게이트 구조로 인해 모델이 복잡해지고, 학습 및 추론 속도가 느려지는 문제가 있습니다.
- 어텐션 메커니즘의 필요성
- 기계 번역 같은 작업에서 LSTM은 문장의 마지막(hidden state)만 활용하는 구조로 인해 정보 손실이 발생할 수 있습니다. 이를 해결하기 위해 등장한 것이 어텐션(Attention) 메커니즘입니다.
트랜스포머의 등장
LSTM의 한계를 극복하기 위해 2017년 "Attention is All You Need" 논문에서 트랜스포머 모델이 등장했습니다. 트랜스포머는 어텐션(Self-Attention) 메커니즘을 기반으로 하며, 입력 데이터를 한 번에 처리할 수 있어 병렬 연산이 가능합니다. 또한, 긴 문맥을 효율적으로 학습할 수 있어 기존 RNN 기반 모델을 뛰어넘는 성능을 보여주었습니다.
Self-Attention: 트랜스포머의 핵심 메커니즘
트랜스포머 모델이 기존 RNN 및 LSTM을 대체할 수 있었던 가장 큰 이유는 바로 Self-Attention(자기-어텐션) 메커니즘 덕분입니다. Self-Attention은 입력 데이터의 각 단어가 문장에서 다른 단어들과 어떻게 연관되는지(weight) 를 동적으로 계산하는 방법입니다. 이를 통해 모델은 긴 문맥을 효율적으로 학습하고, 핵심 정보를 보다 유연하게 추출할 수 있습니다.
Self-Attention의 원리
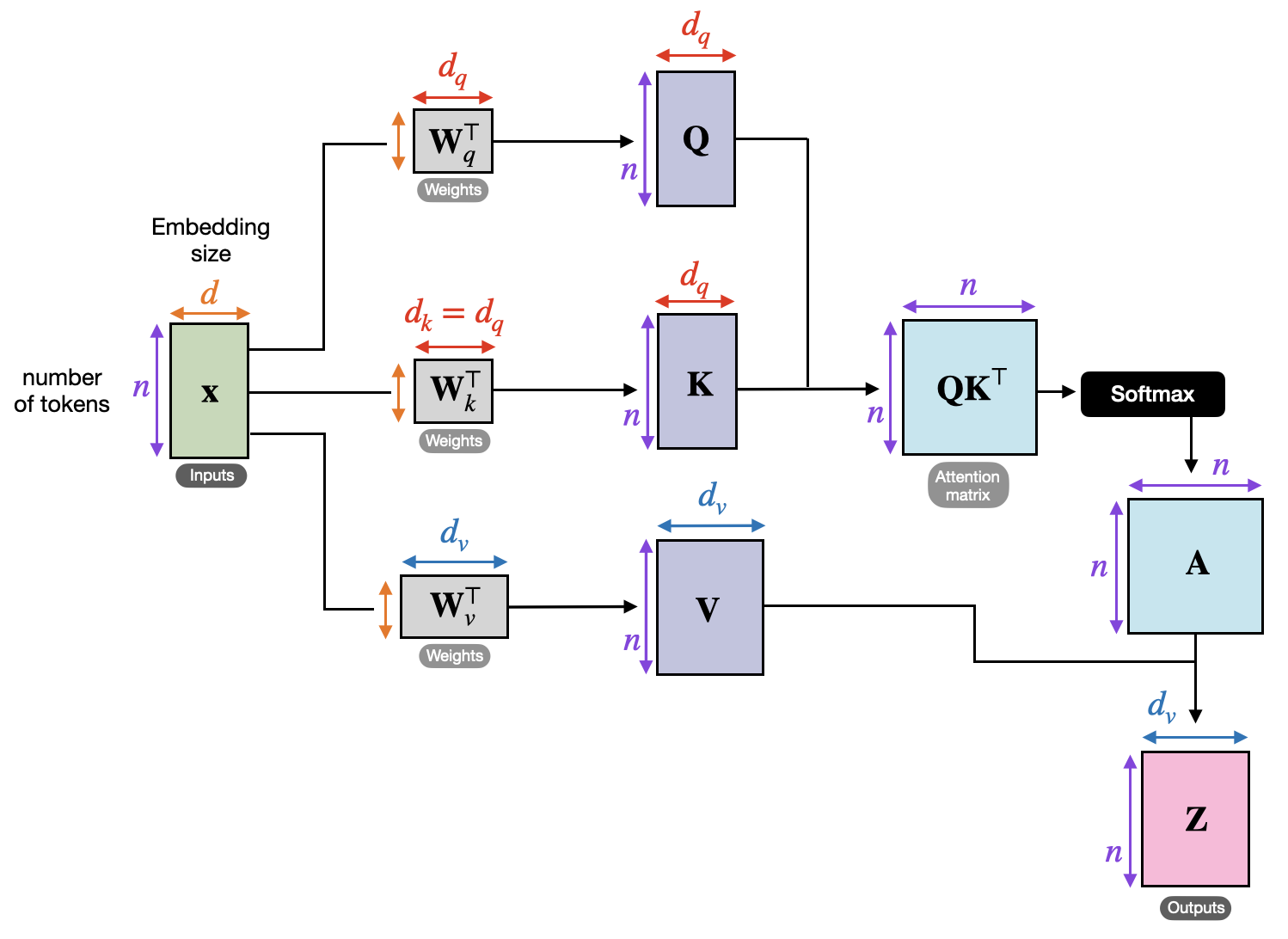
Self-Attention은 주어진 문장에서 각 단어가 다른 단어들과의 관계를 학습하기 위해 쿼리(Query), 키(Key), 값(Value) 세 가지 벡터를 활용합니다.
1. 쿼리(Query), 키(Key), 값(Value) 벡터 생성
각 단어의 임베딩 벡터를 세 개의 행렬(W_q, W_k, W_v)과 곱하여 쿼리(Q), 키(K), 값(V) 벡터를 생성합니다.
$$
Q = X W_q, \quad K = X W_k, \quad V = X W_v
$$
여기서
- Query(Q): 내가 찾고자 하는 정보(현재 단어의 의미)
- Key(K): 데이터베이스의 인덱스(다른 단어들의 의미)
- Value(V): 최종적으로 참고할 정보
2. 어텐션 스코어(유사도) 계산
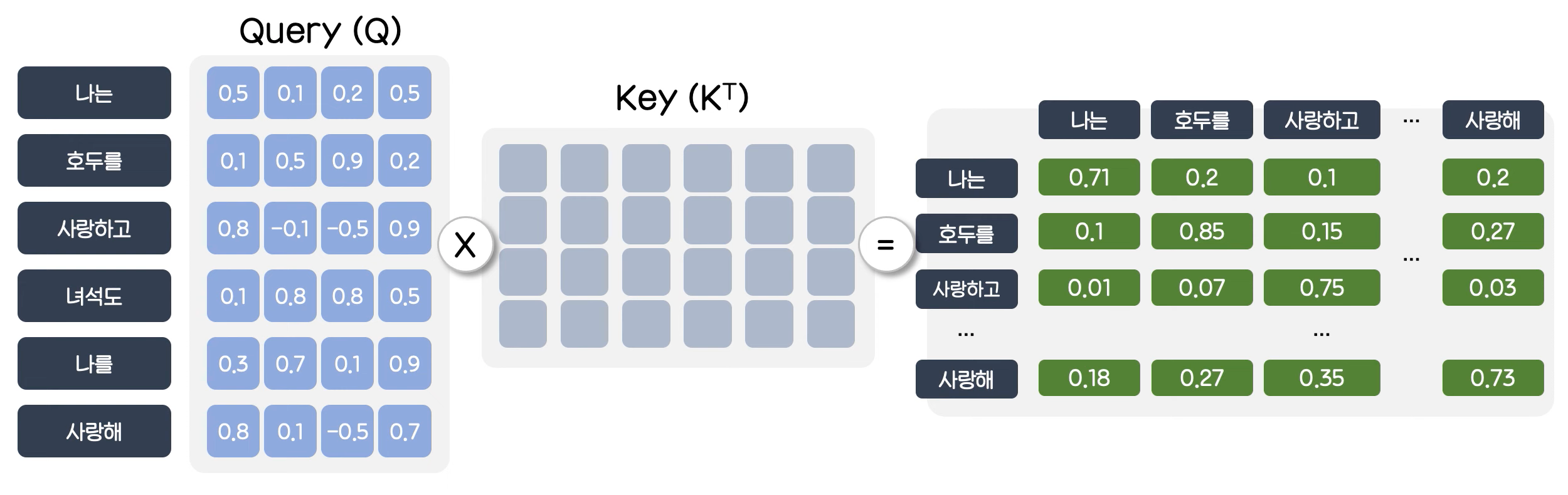
쿼리(Q)와 키(K)의 점곱(dot product)을 수행하여 유사도를 측정합니다.
$$
\text{Attention Score} = QK^T
$$
유사도가 높은 단어일수록 더 중요한 단어로 간주됩니다.
3. Softmax를 통해 가중치 결정
어텐션 점수를 소프트맥스(Softmax) 를 적용하여 확률값(가중치)으로 변환합니다.
$$
\alpha = \text{softmax}(QK^T / \sqrt{d_k})
$$
여기서 $\sqrt{d_k}$ 는 스케일링(Scaling) 기법으로, 큰 숫자로 인해 그래디언트 폭발이 일어나는 것을 방지합니다.
4. 가중치를 반영한 값(Value) 벡터 계산
가중치(α)를 값(V)에 곱하여 최종적으로 어텐션 결과를 얻습니다.
$$
\text{Self-Attention Output} = \alpha V
$$
이를 통해 각 단어는 문맥에 맞게 가중치가 적용된 정보를 얻을 수 있습니다.
Multi-Head Attention: Self-Attention의 확장

Self-Attention이 강력한 기능을 제공하지만, 단일 어텐션만 사용하면 모델이 특정 패턴이나 관계에 집중할 가능성이 있습니다. 이를 해결하기 위해 트랜스포머는 Multi-Head Attention 기법을 도입했습니다.
Multi-Head Attention의 개념
Multi-Head Attention은 Self-Attention을 여러 개의 서로 다른 시각에서 병렬적으로 수행하는 방식입니다. 이를 통해 모델은 다양한 의미 관계를 동시에 학습할 수 있습니다.
Multi-Head Attention의 동작 과정
- 쿼리(Q), 키(K), 값(V) 생성
- 입력 데이터로부터 여러 개의 W_q, W_k, W_v 가중치를 학습하여 각기 다른 헤드를 만듭니다.
- 즉, 서로 다른 학습된 행렬을 통해 여러 개의 독립적인 Self-Attention을 수행합니다.
- 각 헤드별 어텐션 수행
- 각 헤드는 독립적으로 Self-Attention을 수행하여 서로 다른 문맥 정보를 학습합니다.
- 헤드 병합(Concatenation) 및 선형 변환
- 여러 개의 어텐션 결과를 하나로 합친 후, 최종적으로 선형 변환(W_o)하여 출력합니다.
$$
\text{Multi-Head Output} = \text{Concat}(\text{Head}_1, \text{Head}_2, ..., \text{Head}_h) W_o
$$
- 여러 개의 어텐션 결과를 하나로 합친 후, 최종적으로 선형 변환(W_o)하여 출력합니다.
Multi-Head Attention의 장점
- 다양한 문맥 정보 학습
- 단일 어텐션에서는 특정 관계만 학습할 가능성이 있지만, 여러 개의 헤드를 사용하면 다양한 시각에서 문맥을 분석할 수 있습니다.
- 정보 손실 방지
- 단일 어텐션은 특정 패턴만 강조할 수 있지만, 여러 개의 헤드를 병렬적으로 사용하면 보다 일반적인 표현 학습이 가능합니다.
- 복잡한 의미 관계 학습 가능
- 예를 들어, 하나의 헤드는 "주어-동사 관계"를 학습하고, 다른 헤드는 "형용사-명사 관계"를 학습할 수도 있습니다.
정리
Self-Attention은 트랜스포머의 핵심 요소로, 기존 RNN/LSTM보다 빠르고 효율적으로 문맥 정보를 학습할 수 있도록 해줍니다. 하지만 단일 어텐션만 사용하면 모델이 특정 패턴에 과도하게 의존할 가능성이 있기 때문에, 이를 보완하기 위해 Multi-Head Attention이 도입되었습니다. Multi-Head Attention은 서로 다른 시각에서 문맥을 분석하여 더욱 풍부한 표현 학습을 가능하게 합니다.
다음 글에서는 트랜스포머의 전체 구조를 살펴보며 인코더와 디코더의 내부가 어떻게 돌아가는지 더 상세히 알아보겠습니다.
'AI' 카테고리의 다른 글
| vLLM의 핵심 이해: PagedAttention (0) | 2025.03.25 |
|---|---|
| vLLM 이란? (0) | 2025.03.25 |
| 트랜스포머 (Transformer) #3 (0) | 2025.03.24 |
| 트랜스포머 (Transformer) #2 (0) | 2025.02.14 |
| LangChain 이란 무엇인가? (2) | 2024.09.20 |