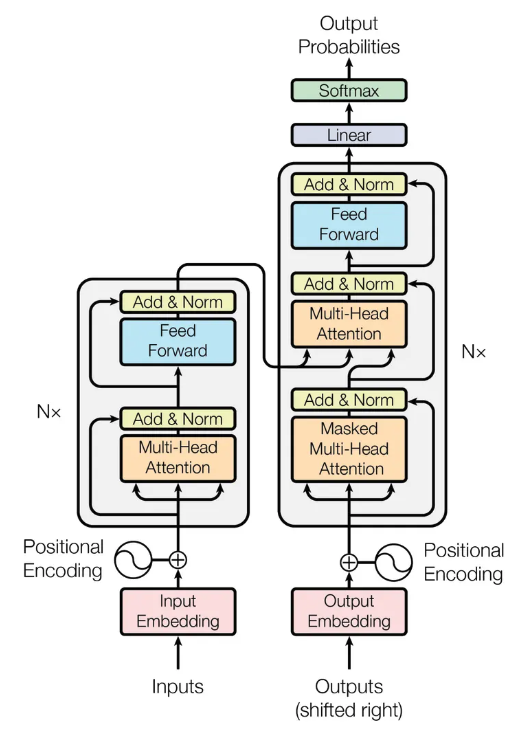
위 그림은 트랜스포머 모델의 전체 아키텍처를 도식화한 것입니다. 트랜스포머는 인코더-디코더 구조로 이루어져 있으며, 각 구성 요소는 멀티 헤드 어텐션(Multi-Head Attention), 잔차 연결(Add & Norm), 그리고 피드 포워드 네트워크(Feed Forward Network)로 구성됩니다. 이 모델의 핵심 개념은 바로 어텐션 메커니즘(Attention Mechanism)으로, 입력 문장의 각 단어가 문맥 속에서 얼마나 중요한지를 효과적으로 학습할 수 있도록 도와줍니다.
이제 트랜스포머 모델이 어떻게 동작하는지 순서대로 살펴보겠습니다.
Input Embedding: 단어를 벡터로 변환하는 과정
트랜스포머(Transformer) 모델에서 입력이 처리되는 첫 번째 단계는 문장을 수치화된 벡터로 변환하는 것입니다. 이 과정은 크게 두 가지 단계로 나뉩니다.
- 토큰화(Tokenization)
문장을 개별 단어(혹은 서브워드 단위)로 나누고, 각 토큰을 고유한 정수 ID로 매핑합니다.
예를 들어, 문장 "나는 호두를 사랑해" 가 있을 때, 모델이 사전에 학습한 단어 사전(vocabulary)이 다음과 같다면:문장은[0, 1, 2]와 같은 정수 시퀀스로 변환됩니다. {"나는": 0, "호두를": 1, "사랑해": 2, ...}- 임베딩(Embedding) 변환
정수 시퀀스를 벡터로 변환하는 과정입니다. 신경망 모델은 숫자로만 연산할 수 있기 때문에, 각 단어를 고정된 크기의 실수 벡터로 매핑하는 임베딩 레이어(Embedding Layer) 를 사용합니다.예를 들어, 다음과 같은 임베딩 행렬 W가 있다고 가정해 보겠습니다.
그러면 문장토큰 ID 임베딩 벡터 0 (나는) [1.0, 0.1, 0.0, ...] 1 (호두를) [0.7, 0.1, ..., 0.5] 2 (사랑해) [0.0, 1.0, ..., -0.3] [0, 1, 2]는 다음과 같이 변환됩니다.여기서 W 행렬의 값은 학습 가능한 파라미터로, 모델이 학습을 통해 최적화합니다. 초기에는 무작위 값이지만, 훈련 데이터를 학습하면서 점점 더 의미 있는 벡터로 변하게 됩니다. [ [1.0, 0.1, 0.0, ...], # "나는" [0.7, 0.1, ..., 0.5], # "호두를" [0.0, 1.0, ..., -0.3] # "사랑해" ]- 트랜스포머 모델에서는 일반적으로 학습 가능한 임베딩 행렬 W 를 사용하여 변환을 수행합니다. 이 행렬은
(어휘 크기, 임베딩 차원 수)형태로 구성되며, 문장 내 각 단어의 정수 ID를 look-up하여 해당하는 벡터를 반환합니다.
포지셔널 인코딩(Positional Encoding)
트랜스포머 모델은 RNN(Recurrent Neural Networks)과 달리 입력 토큰을 한 번에 병렬 처리합니다. 하지만 이 방식에는 문장 내 단어 순서를 고려할 수 없는 문제가 있습니다. 자연어에서는 "나는 호두를 사랑해"와 "호두를 나는 사랑해"가 의미가 다르지만, 트랜스포머는 단순한 임베딩 벡터만 사용하면 이러한 차이를 인식할 수 없습니다.
이를 해결하기 위해 포지셔널 인코딩(Positional Encoding) 을 추가하여 모델이 각 단어의 위치 정보를 학습할 수 있도록 만듭니다.
포지셔널 인코딩의 원리 🧩
포지셔널 인코딩은 각 단어의 위치를 고유한 벡터로 변환하여 임베딩 벡터에 더하는 방식으로 동작합니다.
수식으로 표현하면 다음과 같습니다.
$$
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)
$$
$$
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)
$$
여기서:
- $ pos $는 단어의 위치(Position)
- $ i $는 벡터 차원의 인덱스
- $ d $는 임베딩 차원 수
즉, 위치에 따라 사인(Sin)과 코사인(Cosine) 함수를 적용하여 위치 벡터를 생성합니다. 이 방식은 위치가 커질수록 점진적으로 변화하는 패턴을 가지며, 모델이 상대적인 단어 순서를 학습하는 데 유리합니다.
포지셔널 인코딩 적용 방식 🏗️
생성된 포지셔널 인코딩 벡터는 각 단어의 임베딩 벡터에 단순히 더하는(Addition) 방식으로 적용됩니다.
$$
Z = X + PE
$$
여기서:
- $ X $는 임베딩된 입력 벡터
- $ PE $는 포지셔널 인코딩 벡터
- $ Z $는 위치 정보가 반영된 최종 입력 벡터
이렇게 하면, 같은 단어라도 문장 내 위치에 따라 다른 벡터를 가지게 되므로 트랜스포머가 단어의 순서를 학습할 수 있습니다.
포지셔널 인코딩의 장점 🌟
1️⃣ 순차적 구조 없이도 단어 순서 반영
- RNN처럼 순차적으로 처리할 필요 없이 병렬 연산이 가능하면서도 단어의 순서를 고려할 수 있습니다.
2️⃣ 상대적 위치 정보 학습 가능
- 사인과 코사인 함수의 주기성을 활용해, 모델이 단어 간의 상대적 거리도 학습할 수 있습니다.
3️⃣ 추론 시 길이 확장 가능
- 미리 정의한 최대 길이(
max_len) 내에서 새로운 문장에도 쉽게 적용할 수 있습니다.
인코더(Encoder): 반복되는 트랜스포머의 핵심 구조
트랜스포머의 인코더는 Nx개의 동일한 블록을 반복적으로 쌓는 구조로 이루어져 있습니다. 각각의 인코더 블록은 멀티-헤드 어텐션(Multi-Head Attention) 과 피드 포워드 네트워크(Feed Forward Network, FFN) 를 포함하며, 각 단계마다 잔차 연결(Add & Norm) 을 수행하여 학습을 안정화합니다.
💡 멀티-헤드 어텐션의 세부 동작 방식은 이전 블로그 글에서 다뤘으므로 여기서는 생략합니다.
인코더 블록의 구성
각 인코더 블록은 다음과 같은 단계를 거쳐 입력을 변환합니다.
1️⃣ 멀티-헤드 어텐션 (Multi-Head Attention)
- 입력 벡터에서 자기 어텐션(Self-Attention) 을 수행하여 문맥 정보를 반영한 새로운 벡터를 생성합니다.
- 동일한 입력을 여러 개의 어텐션 헤드(Head)에서 독립적으로 처리한 후, 이를 결합하여 표현력을 높입니다.
2️⃣ Add & Norm (Residual Connection + Layer Normalization)
- 멀티-헤드 어텐션의 출력을 원래 입력에 더하는 잔차 연결(Residual Connection) 을 수행합니다.
- 이어서 Layer Normalization (Layer Norm) 을 적용하여 학습 안정성을 높입니다.
잔차 연결이 중요한 이유?
잔차 연결을 사용하면, 학습 초기에 그라디언트가 너무 작아지면서 발생하는 기울기 소실(Vanishing Gradient) 문제를 완화할 수 있습니다.
3️⃣ 피드 포워드 네트워크 (Feed Forward Network, FFN)
- 어텐션 연산 후 얻은 벡터를 개별적으로 처리하는 두 개의 완전 연결 레이어(Fully Connected Layers) 로 구성됩니다.
- 일반적으로 ReLU 활성 함수를 사용하여 비선형성을 부여합니다.
$$
FFN(x) = \max(0, xW_1 + b_1) W_2 + b_2
$$
이 단계는 개별 토큰의 표현을 강화하는 역할을 합니다.
4️⃣ Add & Norm (Residual Connection + Layer Normalization)
- 피드 포워드 네트워크의 출력을 이전 단계 출력에 더하고, 다시 한 번 Layer Normalization을 적용합니다.
🔁 Nx번 반복: 깊은 인코더 네트워크 형성
위의 과정은 하나의 인코더 블록에서 이루어지며, 트랜스포머에서는 이 블록을 여러 번(Nx) 반복하여 인코더를 구성합니다.
- 논문에서는 기본적으로 Nx = 6 (6개의 인코더 블록)을 사용했습니다.
- 더 깊은 네트워크를 쌓을수록 모델이 더 복잡한 패턴을 학습할 수 있습니다.
💡 이 반복 구조의 의미?
- 인코더 블록이 여러 개 쌓이면서 어텐션과 FFN을 여러 번 거친 결과가 최종 인코더 출력을 형성합니다.
- 초기 단계에서 학습된 단순한 특징이 고차원의 풍부한 의미 표현으로 발전합니다.
- 각 인코더 블록이 점점 더 추상적인 표현을 학습하면서 문장의 의미를 정교하게 인코딩합니다.
디코더 입력: Output Embedding과 Positional Encoding
1️⃣ 디코더의 입력: Shifted Right Output
디코더는 이전 단어를 기반으로 다음 단어를 예측하는 방식으로 동작합니다.
하지만 첫 번째 단어는 이전 단어가 없기 때문에, 시작을 알리는 <START> 토큰만 입력됩니다.
예제: 정답 문장이 다음과 같다면
["나는", "호두를", "사랑해", "<EOS>"]디코더의 입력은 한 칸 오른쪽으로 이동(Shift Right) 하며, 첫 번째 입력은 <START> 토큰 하나만 포함됩니다.
🏗️ 디코더 입력 (Shifted Right)
1st step: ["<START>"]
2nd step: ["<START>", "나는"]
3rd step: ["<START>", "나는", "호두를"]
4th step: ["<START>", "나는", "호두를", "사랑해"] 이처럼 첫 번째 스텝에서는 <START> 토큰만 입력되며,
이후 디코더는 이전까지 생성된 단어들을 입력으로 사용하면서 점진적으로 시퀀스를 확장합니다.
이제 이렇게 변환된 입력을 Embedding + Positional Encoding 과정을 거쳐 벡터로 변환한 후, 디코더 블록으로 전달합니다. 🚀
2️⃣ Output Embedding: 정수 ID를 벡터로 변환
디코더의 입력(Shifted Right Output)은 정수 ID로 변환된 상태이므로, 이를 벡터로 변환하기 위해 임베딩 레이어(Embedding Layer) 를 사용합니다.
이 과정은 인코더의 입력 임베딩과 동일하며, 각각의 정수 ID를 고정된 차원의 밀집 벡터(Dense Vector) 로 변환합니다.
3️⃣ Positional Encoding 추가
디코더 역시 인코더와 마찬가지로 입력 순서 정보가 포함되어 있지 않으므로 Positional Encoding을 더해줍니다.
- 이전에 설명한 것처럼, 사인(Sin)과 코사인(Cosine) 함수를 이용하여 포지션 벡터를 생성합니다.
- 이를 Output Embedding 벡터와 더해(position-wise addition) 디코더가 문장의 순서를 학습할 수 있도록 합니다.
디코더 내부: Masked Multi-Head Attention, 인코더-디코더 어텐션
트랜스포머 디코더는 Nx번 반복되는 동일한 구조의 블록으로 구성되어 있으며, 각 블록은 다음과 같은 순서로 연산을 수행합니다.
- Masked Multi-Head Attention
- Multi-Head Attention (인코더의 출력과 결합됨)
- Feed Forward Network
이 과정이 N번 반복되면서 최종적인 출력을 생성하는 과정이 이루어집니다.
1️⃣ Masked Multi-Head Attention: 미래 단어를 가려야 하는 이유 🤔
디코더에서 첫 번째로 수행되는 어텐션은 Masked Multi-Head Attention 입니다.
이는 디코딩 과정에서 모델이 아직 생성되지 않은 미래 단어를 참고하지 못하도록 하는 역할을 합니다.
🚨 왜 Masking이 필요할까?
- 인코더에서는 입력 문장 전체를 한 번에 처리하므로 모든 단어를 서로 참고할 수 있었습니다.
- 그러나 디코더에서는 왼쪽에서 오른쪽으로 순차적으로 단어를 생성해야 하므로,
- 현재 단어를 예측할 때 이후 단어를 보지 못하도록 해야 합니다.
- Masking을 적용하지 않으면, 모델이 정답을 미리 참조하는 데이터 누수(Data Leakage) 가 발생할 수 있습니다.
🏗️ Masked Attention의 동작 방식
일반적인 어텐션은 Query(질의), Key(키), Value(값) 행렬을 사용하여 아래와 같이 계산됩니다.
$$
\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V
$$
그러나 Masked Multi-Head Attention에서는 미래 단어를 가리기 위해 마스크(masking) 행렬을 추가합니다.
즉, 정답 문장이 ["나는", "호두를", "사랑해"] 라면,
| 현재 단어 | 참조할 수 있는 단어 |
|---|---|
| "나는" | ["나는"] |
| "호두를" | ["나는", "호두를"] |
| "사랑해" | ["나는", "호두를", "사랑해"] |
미래 단어를 가리기 위해 softmax 이전에 -∞ 값을 적용하는 마스킹 연산을 추가합니다.
이렇게 하면 어텐션 점수가 계산될 때 마스킹된 부분은 무한대의 작은 값이 되어, softmax를 거친 후 0이 됩니다.
출력 예시:
tensor([[ 0., -inf, -inf, -inf, -inf],
[ 0., 0., -inf, -inf, -inf],
[ 0., 0., 0., -inf, -inf],
[ 0., 0., 0., 0., -inf],
[ 0., 0., 0., 0., 0.]])이렇게 하면 현재 단어까지만 볼 수 있도록 제한됩니다. ✅
2️⃣ Multi-Head Attention (인코더 결과 이용)
디코더의 두 번째 어텐션은 인코더의 출력과 결합하여 동작하는 Multi-Head Attention 입니다.
이전 단계의 Masked Multi-Head Attention과의 차이점은 다음과 같습니다.
| 어텐션 종류 | Query | Key & Value |
|---|---|---|
| Masked Multi-Head Attention | 디코더의 입력 | 디코더의 입력 |
| Multi-Head Attention (인코더-디코더) | 디코더의 입력 | 인코더의 출력 |
즉, 현재까지 생성된 디코더의 출력(Query) 를 사용하여 인코더에서 나온 Key-Value 쌍과 어텐션을 수행하는 방식입니다.
🏗️ 이 과정이 중요한 이유
- 인코더는 전체 입력 문장에서 정보를 추출하여, 문맥적으로 중요한 부분을 벡터로 저장합니다.
- 디코더는 이 벡터를 활용하여 "이전까지 생성한 단어" 와 "입력 문장에서 중요한 정보" 를 결합하여 더 정확한 출력을 만듭니다.
이제 이 어텐션을 거친 정보는 Feed Forward Network 를 통과한 후, 최종적으로 디코더의 출력을 생성하는 과정으로 이어집니다. 🚀
디코더 결과 처리: Linear → Softmax → Output Probabilities
트랜스포머 디코더의 마지막 단계는 디코더 블록을 거친 출력을 실제 단어로 변환하는 과정입니다.
이 과정은 크게 3단계로 진행됩니다.
- Linear Layer: 디코더 출력을 단어 사전 크기(vocab size)와 동일한 차원의 벡터로 변환
- Softmax: 변환된 벡터를 확률 분포로 변환
- Output Probabilities: 가장 높은 확률을 가진 단어를 선택하여 최종 출력
1️⃣ Linear Layer: 단어 사전 크기로 변환
디코더 블록을 거친 최종 출력 벡터는 고정된 크기(임베딩 차원 d_model)의 연속적인 벡터입니다.
이 벡터를 그대로 사용할 수는 없으므로, Linear 변환을 적용하여 단어 사전 크기(vocab size)와 동일한 차원으로 변환해야 합니다.
📌 이 과정이 필요한 이유
- 디코더의 출력은
d_model차원의 벡터 - 하지만 모델이 예측할 단어는 단어 사전 크기(vocab size) 중 하나여야 함
- 따라서 가중치 행렬 $ W $ 를 곱해 vocab_size 차원의 벡터로 변환
수식으로 표현하면:
$$
Y = X W + b
$$
- $ X $: 디코더의 최종 출력 ($d_{model}$ 차원)
- $ W $: 학습 가능한 가중치 행렬 ($d_{model} \times $vocab size)
- $ b $: 편향 벡터
- $ Y $: 변환된 벡터 (vocab size 차원)
2️⃣ Softmax: 확률 분포로 변환
Linear 레이어를 통과한 출력 벡터는 단어 사전 크기와 동일한 차원을 가지는 숫자 벡터입니다.
이제 Softmax를 적용하여 확률 분포(probability distribution)로 변환합니다.
Softmax 공식
$$
P(y_i) = \frac{e^{y_i}}{\sum_{j} e^{y_j}}
$$
여기서:
- $ P(y_i) $는 단어 $ y_i $ 가 정답일 확률
- $ y_i $ 는 Linear 레이어를 통과한 벡터 값
- 모든 단어의 확률 합이 1이 되도록 정규화
📌 Softmax를 적용하면?
- 모델이 예측한 벡터가 각 단어에 대한 확률 값으로 변환됨
- 가장 높은 확률을 가진 단어를 선택하면 최종 출력이 됨
예를 들어, 단어 사전이 ["나는", "호두를", "사랑해"] 세 개만 있다고 가정했을 때:
Linear 출력: [3.2, 1.8, 2.5] (가중치 연산 결과)
Softmax 출력: [0.65, 0.12, 0.23] (확률로 변환됨)👉 가장 확률이 높은 "나는" (0.65) 가 선택됨 ✅
3️⃣ Output Probabilities: 최종 단어 선택
Softmax를 적용한 후, 가장 높은 확률을 가진 단어를 최종 출력으로 선택합니다.
- Greedy Decoding: 확률이 가장 높은 단어를 바로 선택
- Beam Search: 여러 후보를 고려하면서 더 나은 문장을 탐색
📌 이 과정에서 중요한 점
- Softmax 확률이 가장 높은 단어를 선택하는 방식으로 문장이 점차 생성됨
- 반복적으로 새로운 단어를 예측하면서 최종 문장을 완성함
'AI' 카테고리의 다른 글
| vLLM의 핵심 이해: PagedAttention (0) | 2025.03.25 |
|---|---|
| vLLM 이란? (0) | 2025.03.25 |
| 트랜스포머 (Transformer) #3 (0) | 2025.03.24 |
| 트랜스포머 (Transformer) #1 (0) | 2025.02.13 |
| LangChain 이란 무엇인가? (2) | 2024.09.20 |