트랜스포머를 공부하다 더 깊게 알게된(잘못 이해, 몰랐던) 사실 간단하게 정리
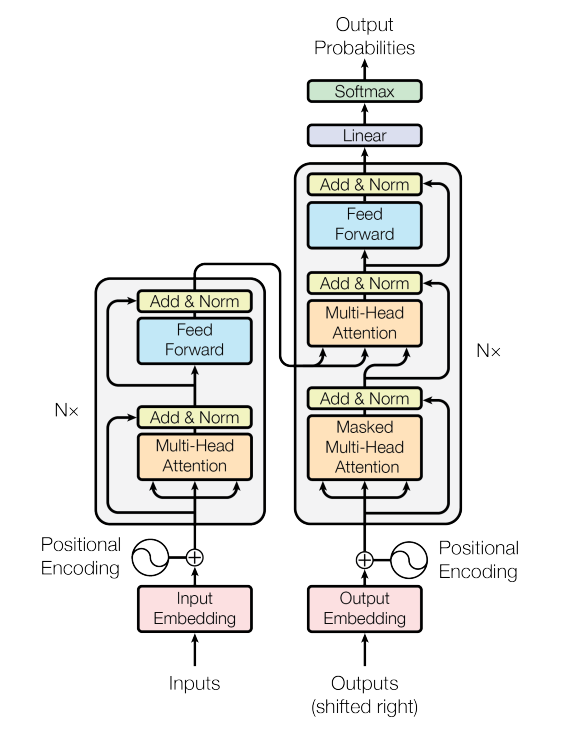
- 우리가 일반적으로 쓰는 GPT 같은 LLM은 디코더 only 구조이다. 일반적으로 트랜스포머 구조도 이미지를 보면 아래와 같이 인코더, 디코더 구조로 나오는데. 인코더만, 디코더만, 인코더 디코더 둘 다 사용 모두 용도에 따라 케이스가 다르다.
- Attention 메커니즘에서 Q, K, V가 사용되는데, I am a boy 라는 입력이 왔을때 "I" "am" "a" "boy"가 쪼개진 토큰이라 가정하면. "I" 토큰에 대해 계산할때 Q에는 "I"값만 들어가고 K, V에는 4개 토큰 모두 값이 들어가서 계산됨. 이것이 멀티해드로 각각 다른 가중치 값이 적용되어 계산되고 Concatenate 같은 기법으로 하나의 결과로 도출됨. 이게 하나의 토큰 Q에 대한 작업(주황색 영역)임. 이것이 모든 토큰에 대해서 병렬적으로 계산되는거임.
- Nx로 표시된 부분이 레이어 부분이다. 즉 해당 영역의 작업의 결과가 다시 input으로 들어가 N개의 레이어를 통해 N번 반복되어 최종 결과가 도출된다. 즉, 각 W_Q, W_K, W_V, FFN의 가중치 및 기타 파라미터 등 모든 값이 레이어마다 다르다.
- "I"의 1층 레이어의 결과 값이 H1, "am"의 1층 레이어 결과 값이 H2 그뒤로 H3, H4라고 할때 이것이 레이어 2의 입력값으로 들어감. 그리고 레이어 2에서 K_all = [H₁ × W_K, H₂ × W_K, H₃ × W_K, ...], V_all = [H₁ × W_V, H₂ × W_V, H₃ × W_V, ...] 이런식으로 K, V값을 만드는데 사용됨. 즉, 레이어마다 K, V 값이 다르게 만들어지고 이것은 재활용이 가능하기 때문에 모든 레이어의 K,V 값이 캐싱됨.
- 트랜스포머에서 첫번째 계산(모든 레이어 계산 포함)이 완료되고 또 그다음 말을 예측하기 위해서 다시 순환할때는 이전의 토큰의 Q값을 계산할 필요가 없음. 다시 설명하자면, 만약 맨처음에 "I am a"를 입력했다고 했을 때 다음말인 "boy"를 예측하는 작업은 사실상 마지막 토큰인 "a" Q에 대한 트랜스포머 작업뿐임. 그런데도 "I"와 "am"에 대한 작업도 필요한이유는 모든 레이어에서의 K, V 값을 만들어야하는데 여기에는 모든 토큰에 대한 값이 담기기 때문임. 그래서 "I"와 "am" 모두 모든 레이어에 대해서 계산하고 각 레이어에 대한 K, V 값을 완성시켜야 하는거임 물론 "a"도 포함해서. 그래서 결과 적으로 LLM이 답변을 완성하는 과정중 첫번째 계산에서는 입력에 대한 모든 토큰에 대해서 K, V값을 계산해야하기 때문에 오래걸림.
- 첫번째 순환 "I am a" 넣고 결과로 "boy"가 나왔다고치고 그다음으로 마침표"."가 나온다고 가정해보자. 이때 첫번째 순환에서 "I", "am", "a"에 대한 모든 K, V가 완성됐으니 계산할필요 없고 그대로 재사용하면됨. 그리고 이제 Q값으로 "boy"가 들어와서 이 "boy"에 대한 K, V 값만 각 레이어에서 기존의 값에 붙여서 완성시키고 다시 캐싱해서 재사용하면됨. 즉 두번째 순환부터는 입력의 앞쪽 토큰들에 대해서 K, V값을 다시 계산할 필요가 없으니 속도가 맨처음보단 빨라짐.
아래는 GPT가 위의 내용 보기좋게 정리해준 글
⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️
디코더-Only 구조인 GPT는 어떻게 작동할까?
우리가 자주 사용하는 GPT 모델은 Transformer 구조 중 디코더(Decoder)만 사용하는 구조입니다. Transformer의 원래 구조를 보면 인코더(Encoder)와 디코더(Decoder)로 나뉘지만, 용도에 따라 인코더만 쓰거나, 디코더만 쓰거나, 혹은 둘 다 사용하는 경우도 있습니다.
- 예)
- 인코더만 사용하는 모델: BERT (문장 이해용)
- 디코더만 사용하는 모델: GPT (텍스트 생성용)
- 인코더-디코더 구조: T5, BART (텍스트 변환용)
1. GPT의 핵심: Attention 메커니즘
Transformer의 핵심은 Self-Attention, 즉 어텐션 메커니즘입니다. 이 과정에서 Query(Q), Key(K), Value(V) 세 가지 벡터가 사용됩니다.
예를 들어, 아래와 같이 문장이 입력되었다고 가정해봅시다.
I am a boy이 문장은 총 4개의 토큰으로 분해됩니다. 이때, 각 토큰에 대해 Q는 해당 토큰의 정보만, K와 V는 전체 토큰의 정보를 포함하여 계산됩니다.
예시: "I" 토큰의 Attention 계산
Q = Q("I")
K = [K("I"), K("am"), K("a"), K("boy")]
V = [V("I"), V("am"), V("a"), V("boy")]이러한 계산은 멀티-헤드 어텐션(Multi-Head Attention)으로 병렬 처리되며, 결과는 Concatenate 후 Linear Layer를 거쳐 하나의 출력으로 나옵니다.
이 과정은 모든 토큰에 대해 병렬적으로 진행됩니다.
2. Nx는 무엇일까? → 레이어 개수
Transformer 구조에서 종종 보이는 Nx는 레이어 개수를 의미합니다. 즉, 동일한 구조의 블록을 N번 반복하여 더 깊은 표현을 학습하도록 구성됩니다.
H₁ = 첫 번째 레이어에서의 "I" 결과
H₂ = 첫 번째 레이어에서의 "am" 결과
...이렇게 얻어진 결과들은 다음 레이어의 입력이 됩니다. 중요한 점은:
각 레이어마다 W_Q, W_K, W_V, FFN 등의 가중치 파라미터가 전부 다릅니다.
즉, 레이어가 반복되더라도 파라미터는 공유하지 않습니다.
3. 레이어별 K, V는 캐싱된다
예를 들어, 1층의 결과가 다음과 같다면:
H₁ = 결과("I")
H₂ = 결과("am")
H₃ = 결과("a")
H₄ = 결과("boy")2층 레이어에서의 K, V는 이렇게 계산됩니다:
K_all = [H₁ × W_K, H₂ × W_K, H₃ × W_K, H₄ × W_K]
V_all = [H₁ × W_V, H₂ × W_V, H₃ × W_V, H₄ × W_V]이처럼 레이어마다 K, V가 다르게 생성되며, 재사용(캐싱)이 가능합니다.
이 캐시 기능은 GPT가 빠르게 다음 토큰을 예측할 수 있도록 해주는 핵심입니다.
4. 첫 번째 순환은 왜 느릴까?
예를 들어 처음에 다음 입력이 주어졌다고 해봅시다:
I am aGPT는 다음 토큰 "boy"를 예측해야 합니다. 이때의 작업은 단순히 "a"에 대한 예측만이 아니라 모든 레이어에서의 K, V를 만들어야 하기 때문에 다음과 같은 계산이 필요합니다:
- "I" → 모든 레이어에서 K, V 생성
- "am" → 모든 레이어에서 K, V 생성
- "a" → 모든 레이어에서 K, V 생성따라서, 첫 번째 예측 시에는 모든 이전 토큰에 대한 K, V 계산이 필요해서 시간이 많이 소요됩니다.
5. 이후 순환은 왜 빨라질까?
이제 "boy"가 생성되었고, 다음으로 "."을 예측한다고 해봅시다.
이때는 이전 토큰들인 "I", "am", "a"는 이미 모든 레이어에서 K, V가 계산되어 캐시에 저장되어 있기 때문에 다시 계산할 필요가 없습니다.
- 기존 캐시: K, V for "I", "am", "a"
- 추가 작업: "boy"의 K, V만 각 레이어에 추가이렇게 해서 두 번째 순환부터는 새로 들어온 토큰에 대해서만 Q, K, V 계산이 수행되고, 나머지는 재사용되므로 훨씬 빠르게 작동합니다.
정리: GPT의 동작 흐름
1. 첫 입력이 들어오면 → 모든 토큰에 대해 모든 레이어에서 K, V 계산 → 캐싱
2. 다음 토큰 예측 → 새로 들어온 토큰만 Q, K, V 계산 → 기존 K, V와 함께 사용
3. 반복하면서 답변 생성 → 점점 속도가 빨라짐마무리
GPT와 같은 LLM이 어떻게 작동하는지 이해하려면 Attention 구조뿐만 아니라 레이어별 구조, 캐시 재활용, 초기 연산의 복잡성 등을 함께 보는 것이 중요합니다. GPT는 이러한 정교한 구조 덕분에 빠르고 효율적으로 다음 단어를 예측할 수 있는 것이죠.
궁금한 점이 있다면 댓글로 남겨주세요!
'AI' 카테고리의 다른 글
| vLLM의 핵심 이해: PagedAttention (0) | 2025.03.25 |
|---|---|
| vLLM 이란? (0) | 2025.03.25 |
| 트랜스포머 (Transformer) #2 (0) | 2025.02.14 |
| 트랜스포머 (Transformer) #1 (0) | 2025.02.13 |
| LangChain 이란 무엇인가? (2) | 2024.09.20 |